YAFFS (Yet Another Flash File System)
Version 0.3
Charles Manning (and Wookey), December 2001
Revision History
V0.0 20/12/01 First Draft
|
V0.1 |
11/01/02 |
Minor corrections & cosmetics. |
|
V0.2 |
28/01/02 |
Added observations about inodes, file headers and hard links. |
|
V0.3 |
26/02/02 |
W:Added some general observations on compatibility, partitions and bootloading. |
Scope
The purpose of this document is to outline a potential NAND-friendly file system for Linux.
Background
There are already various flash-file systems (FFSs) or block drivers for flash (on top of which a regular FS runs). There are pros and cons with all of these.
Flash memory has quite a few constraints which will not be addressed here. Various approaches are available to work around these constraints to provide a file system. It is important to recognise that "flash" includes both NOR and NAND flash which have different sets of constraints. It is easy to be mislead by the generic term "flash" into thinking that approaches appropriate for NOR flash are immediately suitable for NAND flash.
The NAND block drivers (eg. SmartMedia [currently not available for Linux] and DiskOnChip NFTL) typically use FAT16 as the file system. This isn't too robust and nor is it that flash-friendly. These block drivers provide a logical to physical mapping layer to emulate rewritable blocks that look like disk sectors. When used with FAT16, these file systems work reasonably well. They have a low memory footprint and scale well. Like all FAT based systems they are prone to corruption ("lost clusters etc").
The other approach is to design an entire file system which does not work through a block driver layer and is flash-friendly. This allows more scope to work around issues.
Currently, two Linux file systems that support NOR flash very well are JFFS and its derivative JFFS2. Both of these are based on the principles of journaling (hence the leading J) which significantly increases robustness - a particularly important feature in embedded systems. Unfortunately neither of these file systems scale particularly well in both boot time and RAM usage. Scaling is particularly relevant when one considers that a 16MB NOR array would be considered large while a 128MB NAND is available as a single chip.
JFFS requires a RAM-based jffs_node structure for each journalling node in the flash. Each of these nodes is 48 bytes. JFFS2 makes a significant improvement here by reducing the equivalent structure (jffs2_raw_node_ref) to 16 bytes. Still, at say an average node-size of 512 bytes, a 128MB NAND might need 250000 of these ... 4MB!
Both JFFS and JFFS2 require scanning the flash array at boot time to find the journaling nodes and determine the file structures. Since NAND is large, slow, serially accessed and needs ECC this does not scale well and will take an unacceptably long boot time for the target systems. As a thumb-suck, the scanning of a 128MB NAND array might take approx 25 seconds.
The intentions of the design sketched here are:
-
Be NAND-flash friendly.
-
Robustness through journaling strategies.
-
Significantly reduce the RAM overheads and boot times associated with JFFSx.
This FS is intended primarily for internal NAND rather than removable NAND (SM cards). On removable SM cards Smartmedia compatibility is likely to be important so SM/FAT will normally be used, although of course YAFFS makes a lot of sense if reliability is more important than compatibility.
Overview
Here follows a simplified overview of YAFFS.
YAFFS uses a physical flash format similar to SmartMedia. This is done for various reasons:
-
Some of the formatting, eg placement of bad block markers is determined by the NAND manufacturers and can't be changed.
-
Potential to reuse code.
-
If it ain't broke don't fix.
Some of the fields are obviously different to reflect the different usage. Despite the similarities YAFFS is not actually compatible with SM/FAT. SM cards need to be reformatted to switch from using SM/FAT to YAFFS or vice versa.
File data is stored in fixed size "chunks" consistent with the size of a page (ie. 512 bytes). Each page is marked with a file id and chunk number. These tags are stored in the "spare data" region of the flash. The chunk number is determined by dividing the file position by the chunk size.
When data in a file is overwritten, the relevant chunks are replaced by writing new pages to flash containing the new data but the same tags. The overwritten data is marked as "discarded".
File "headers" are stored as a single page, marked so as to be differentiated from data pages.
Pages are also marked with a short (2 bit) serial number that increments each time the page at this position is incremented. The reason for this is that if power loss/crash/other act of demonic forces happens before the replaced page is marked as discarded, it is possible to have two pages with the same tags. The serial number is used to arbitrate.
A block containing only discarded pages (termed a dirty block) is an obvious candidate for garbage collection. Otherwise valid pages can be copied off a block thus rendering the whole block discarded and ready for garbage collection.
In theory you don't need to hold the file structure in RAM... you could just scan the whole flash looking for pages when you need them. In practice though you'd want better file access times than that! The mechanism proposed here is to have a list of __u16 page addresses associated with each file. Since there are 218 pages in a 128MB NAND, a __u16 is insufficient to uniquely identify a page but is does identify a group of 4 pages - a small enough region to search exhaustively. This mechanism is clearly expandable to larger NAND devices - within reason. The RAM overhead with this approach is approx 2 bytes per page - 512kB of RAM for a whole 128MB NAND.
Boot-time scanning to build the file structure lists should require just one pass reading NAND. Since only the the spare data needs to be read, this should be relatively fast ( approx 3 seconds for 128MB). Improvements can be achieved by partitioning the NAND. ie. mount the critical partition first then mount the data partition afterwards.
Various runtime improvements can be achieved by changing the "chunk size" to 1024 bytes or more. However this would likely reduce flash efficiency. As always, life is a compromise....
Spare area details
The following table summarizes the layout of the spare area of each page.
Byte #SmartMedia usageYAFFS usage
|
0..511 |
Data |
Data. either file data or file header depending on tags |
|
512..515 |
Reserved |
Tags |
|
516 |
Data status byte. Not used in SM code from Samsung |
Data status byte. If more than 4 bits are zero, then this page is discarded. |
|
517 |
Block status byte |
Block status byte |
|
518..519 |
Block address |
Tags |
|
520..522 |
ECC on second 256 bytes part of data |
ECC on second 256 bytes of data |
|
523..524 |
Block address |
Tags |
|
525..527 |
ECC on first 256 bytes part of data |
ECC on first 256 bytes part of data |
The block status is a reserved value that shows whether the block is damaged.
The data status tracks whether the page is valid. If less than 4 bits are zero, then the page is valid otherwise it is discarded.
There are 8 bytes (64 bits) for use by YAFFS tags. This is partitioned as follows:
Number of bitsUsage
|
18 |
18-bit file id. ie. Limit of 218 (over 260000) files. File id 0 is not valid and indicates a deleted page. File Id 0x3FFFF i is also not valid. |
|
2 |
2-bit serial number. |
|
20 |
20-bit page id within file. Limit of 220 pages per file. ie. over 500MB file max size. Page id 0 means the file header for this file. |
|
10 |
10-bit counter of the number of bytes used in the page. |
|
12 |
12-bit ECC on tags. |
|
2 |
Unused. Keep as 1. |
|
64 |
Total |
A bit of explanation on the usage of some of these fields:
file Id is synonymous with inode.
The serial number is incremented each time a page with the same file_id:page_id is rewritten (because of data changes or copy during garbage collection). When a page is replaced, there is a brief period during which there are two pages with the same id. The serial number resolves this. Since there should never be a difference of less than more than one, a two-bit counter is sufficient to determine which is the current page.
When the page is rewritten, the file id, these data status byte and the 12-bit ECC are all written to zero.
The byte counter indicates how many bytes are valid in this page. Since the page would not exist if it contains zero bytes, this field should thus hold 512 for all pages except the last page in the file. The use of counters means that the file length integrity is preserved while the file is open without having to constantly update the file length in the file header. The file header only needs to be refreshed when the file is closed (rather than whenever it is appended to). This field is wide enough to allow expansion to 1024-byte "chunks".
File "headers" come in two flavours:
-
file info ( the mode, ower id, group id, length,...)
-
the hard link(s) that refers to the file.
A directory also appears as a file (ie. has an inode and hard link(s)) but has no data.
The 12-bit ECC applies to only the tag data uses a similar algorithm to the 22-bit ECCs used for file system data. They are kept independent.
RAM data details
Block management details are reasonably obvious and, I feel, don't need to be addressed here apart from stating that there will be a structure to track block status (eg. number of pages in use, failed blocks, and which are candidates for garbage collection etc).
The files need an indexing structure of sorts to locate and track the pages in the file. Some sort of tree structure should work rather well. The look-up needs to be quite efficient in both CPU time and space.
Page allocation and garbage collection
Pages are allocated sequentially from the currently selected block. When all the pages in the block are filled, another clean block is selected for allocation. At least two or three clean blocks are reserved for garbage collection purposes. If there are insufficient clean blocks available, then a dirty block ( ie one containing only discarded pages) is erased to free it up as a clean block. If no dirty blocks are available, then the dirtiest block is selected for garbage collection.
Garbage collection is performed by copying the valid data pages into new data pages thus rendering all the pages in this block dirty and freeing it up for erasure. I also like the idea of selecting a block at random some small percentage of the time - thus reducing the chance of wear differences.
Relative to NOR, NAND writes and erases very fast. Therefore garbage collection might be performed on-demand (eg. during a write) without significant degradation in performance. Alternatively garbage collection might be delegated to a kernel tasklet.
Relative to JFFSx, the garbage collection presented here is incredibly simple - thanks mainly to the use of fixed-size pages instead of journaling nodes.
Flash writing
As presented here, YAFFS only writes to the page's data area once and to the spare area twice (once when new page is written and once when it gets stomped on) before an erasure. This is within the limits of the most restrictive NAND flashes.
Wear levelling
No wear levelling is explicitly used here. Instead we rely on two "strategies":
-
Reserving some blocks to cater for failure. You need to do this anyway with NAND. The main purpose behind wear levelling is to prevent some blocks getting more wear and failing. Since we expect, and handle, failure this is no longer as important.
-
The infrequent random block selection should prevent low-wear blocks getting "stuck".
Partitioning
Partitioning is not included in this spec, but could be added if required.
Bootloading
Bootloaders cannot just read files direct from NAND due to the high probability of bad blocks. Because YAFFS is quite simple it will be relatively straightforward for bootloaders to read from it (eg reading a kernel).
Conclusion
YAFFS is very simple. It is also NAND-friendly, is relatively frugal with resources (especially RAM) and boots quickly. Like JFFSx it has journaling which makes it far more robust than FAT.
While it might seem high-risk to develop YAFFS, it is probably about the same amount of effort as implementing changes to JFFS to get it to work effectively within the constraints of NAND. A resulting JFFSx system would still require significant amounts of RAM and have long boot times.
While YAFFS is indeed a new file system internally, much of the file system glue code (including inode management, link management etc) can likely be stolen from JFFSx.
YAFFS Development Notes
Build options
Yaffs can be built as either a kernel module (ie. a Linux file system) or as an application.
Of course the goal is to build yaffs as a file system running on top of real NAND flash, but yaffs can be built to run on a RAM emulation layer for in-kernel testing without NAND flash in the system.
Building as an application allows the yaffs_guts algorithms to be tested/debugged in a more friendly debugging environment. The test harness is in yaffsdev.c
Trying it out
YAFFS can be built to run with either mtd or RAM emulation, or both. The file system that interfaces to mtd is called yaffs, the file system that uses internal ram is called yaffsram. YAFFS simultaneously supports both if they are enabled.
-
Hack the Makefile and change the KERNELDIR define to your kernel directory.
-
If you don't have mtd support in your kernel, then you might need to turn off USE_MTD otherwise the yaffs module might not load.
-
Type make clean; make to build yaffs
-
Load yaffs as a module by typing /sbin/insmod yaffs.o (ya gotta be root!).
-
Create a mount point eg. mkdir /mnt/y
-
To mount the RAM emulation version of yaffs, mount -t yaffsram none /mnt/y
-
Alternatively, to mount the mtd version of yaffs, mount -t yaffs /dev/mtd0 /mnt/y
YAFFS Data structures
All data types are defined in yaffs_guts.h
Yaffs uses the following major objects:
-
yaffs_Object: A yaffs_Object can be a file, directory, symlink or hardlink. The yaffs_Objects "know" about their corresponding yaffs_ObjectHeader in NAND and the data for that object. yaffs_Objects also bind together the directory structure as follows:
-
parent: pointer to the yaffs_Object that is a parent of this yaffs_Object in the directory structure.
-
siblings: this field is used to link together a list of all the yaffs_Objects in the same directory.
-
children: if the object is a directory, then children holds the head of the list of objects in the directory.
-
yaffs_Tnode: yaffs_Tnodes form a tree structure that speeds up the search for data chunks in a file. As the file grows in size, the levels increase. The Tnodes are a constant size (32 bytes). Level 0 (ie the lowest level) comprise 16 2-byte entries giving an index used to search for the chunkId. Tnodes at other levels comprise 8 4-byte pointer entries to other tnodes lower in the tree.
-
yaffs_Device: this holds the device context and is in some ways analogous to the VFS superblock. It stores the data used to access the mtd as well as function pointers to access the NAND data.
The Tnodes and Objects are allocated in groups to reduce memory allocation/freeing overheads. Freed up tnodes and objects are kept in a free list and re-used.
yaffs_Object
struct yaffs_ObjectStruct
{
__u8 fake:1; // A fake object has no presence on NAND.
__u8 renameAllowed:1; // Are we allowed to rename it?
__u8 unlinkAllowed:1; // Are we allowed to unlink it?
__u8 dirty:1; // the object needs to be written to flash
__u8 valid:1; // When the file system is being loaded up, this
// object might be created before the data
// is available (ie. file data records appear before the header).
__u8 serial; // serial number of chunk in NAND. Store here so we don't have to
// read back the old one to update.
__u16 sum; // sum of the name to speed searching
struct yaffs_DeviceStruct *myDev; // The device I'm on
struct list_head hashLink; // list of objects in this hash bucket
struct list_head hardLinks; // all the equivalent hard linked objects
// live on this list
// directory structure stuff
struct yaffs_ObjectStruct *parent; //my parent directory
struct list_head siblings; // siblings in a directory
// also used for linking up the free list
// Where's my data in NAND?
int chunkId; // where it lives
__u32 objectId; // the object id value
__u32 st_mode; // protection
__u32 st_uid; // user ID of owner
__u32 st_gid; // group ID of owner
__u32 st_atime; // time of last access
__u32 st_mtime; // time of last modification
__u32 st_ctime; // time of last change
yaffs_ObjectType variantType;
yaffs_ObjectVariant variant;
};
Obvious stuff skipped....
fake, renameAllowed, unlinkAllowed are special flags for handling "fake" objects which live in the file system but do not live on NAND. Currently there are only two such objects: the root object and the lost+found directory. None of these may be renamed or unlinked.
serial, sum: see yaffs_ObjectHeader.
dirty indicates that the object's contents has changed and a new yaffs_ObjectHeader must be written to flash.
valid indicates that the object has been loaded up. This is only used during scanning (yaffs_Scan()) since we can know of an object's existance - and thus need to create the object header - before we encounter the associated yaffs_ObjectHeader.
hashlink is a list of Objects in the same hash bucket.
The four variants hold extra info:
Files hold the file size and the top level and pointer to the tnode tree for the file.
Directories hold a list of children objects.
Symlinks hold a pointer to the alias string. This is probably inefficient, but that probably does not matter since we don't expect to see many of these.
Hardlinks hold information to identify the equivalent object.
File structure (tnodes)
File structures are done with a tiered indexing structure
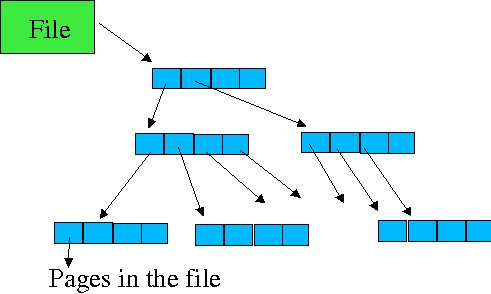
The file structure is maintained by a tree structure. Depending where it is in the tree, each tree node (tnode) (the blue/things) holds either:
-
.... if it is at the lowest level, then 16 __u16s which identify the page.
-
.... if it is at a higher level (ie an internal tnode), then 8 pointers to lowest-level tnodes.
When the file starts out, it is assigned only one low-level tnode. When the file expands past what a single tnode can hold, then it is assigned a second tnode and an internal node is added to point to the two tnodes. As the file grows, more low-level tnodes and high level tnodes are added.
Traversing the tnode tree to find a particular page in a file is quite simple: each internal tnode is selected from by using 3 bits of the page offset in the file. The level 0 page resolves 4 bits.
For example, finding page 0x235 (ie. the one starting at file position 0x46800 would proceed as follows:
0x235 is 0000001000110101, partitioned as follows. 000.000.100.011.0101
LevelBitsSelected value
|
3 or more if they exist |
>= 10 |
Zero |
|
2 |
9 to 7 |
100 binary = 4 |
|
1 |
6 to 4 |
011 binary = 3 |
|
0 |
3 to 0 |
0101 binary = 5 |
Free tnodes are stored in a list. When the list is exhausted, more are allocated.
Each tnode takes 32 bytes. Each file needs at least one level 0 tnode. How many do we need? A full 16MB file system needs at least 16MB/512/16 = 2000 level zero tnodes. More for internal tnodes. More for files smaller than optimal.
The tree grows as required. When the file is resized to a smaller size then it is pruned.
NAND data
Data is stored on NAND in "chunks". Currently each chunk is the same size as a NAND flash page (ie. 512 bytes + 16 byte spare). In the future we might decide to allow for different chunk sizes. Chunks can hold either:
-
A yaffs_ObjectHeader. This is the way a yaffs_Object gets stored on NAND.
-
A chunk of file data.
The 16 byte spare area contains:
-
8 bytes of tags,
-
6 bytes of ECC data
-
1 byte block status (used to identify damaged blocks)
-
1 byte data status (currently unused).
The tags are made up as follows:
typedef struct
{
unsigned chunkId:20; //chunk number in file
unsigned serialNumber:2; //serial number for chunk
unsigned byteCount:10; //number of bytes of data used in this chunk
unsigned objectId:18; //the object id that this chunk belongs to.
unsigned ecc:12; //ECC on tags
unsigned unusedStuff:2; //unused
} yaffs_Tags;
A chunkId of zero indicates that this chunk holds a yaffs_ObjectHeader. A non zero value indicates that this is a data chunk and the position of the chunk in the file (ie. the first chunk - at offset 0 - has chunkId 1). See yaffs_guts.c:yaffs_Scan () to see how this is done.
When a chunk is replaced (eg. file details changed or a part of a file was overwritten), the new chunk is written before the old chunk is deleted. This means that we don't lose data if there is a power loss after the new chunk is created but before the old one is discarded, but it does mean that we can encounter the situation where we find both the old and the new chunks in flash. The serialNumber is incremented each time the chunk is written. 2 bits is sufficient to resolve any ambiguity.
bytecount applies only to data chunks and tells how many of the data bytes are valid.
objectId says which object this chunk belongs to.
ecc is used to perform error correction on the tags. Another ecc field is used to error correct the data.
yaffs_ObjectHeader
typedef struct
{
yaffs_ObjectType type;
// Apply to everything
int parentObjectId;
__u16 sum; // checksum of name
char name[YAFFS_MAX_NAME_LENGTH + 1];
// Thes following apply to directories, files, symlinks - not hard links
__u32 st_mode; // protection
__u32 st_uid; // user ID of owner
__u32 st_gid; // group ID of owner
__u32 st_atime; // time of last access
__u32 st_mtime; // time of last modification
__u32 st_ctime; // time of last change
// File size applies to files only
int fileSize;
// Equivalent object id applies to hard links only.
int equivalentObjectId;
// alias only applies to symlinks
char alias[YAFFS_MAX_ALIAS_LENGTH + 1];
} yaffs_ObjectHeader;
A yaffs_ObjectHeader is stored in NAND for every yaffs_Object.
type holds the type of yaffs_Object (file,directory,hardlink or symlink).
parentObject is the objectId of this object's parent. name holds the object's name. Together these form the directory structure of the file system. Also worth mention is sum. This is a "checksum" on the name which speeds directory searching (ie. when searching the directory we only compare the name for those entries where sum matches).
Obvious stuff skipped....
equivalentObjectId is used by hardlinks. A hardlink to an object uses this field to specify the object that this links to. This way of doing things is a bit different than the normal Linux way of doing things (ie. keeping the links distinct from the inode) but is simpler and uses less space except for a few corner cases with hardlinks.
alias is used by symlinks to hold the symlink alias string. This limits the size of the symlink alias. In future we should expand YAFFS to use data chunks to store aliases too long to fit into the yaffs_ObjectHeader.
NAND Interface
All NAND access is performed via four functions pointed to by yaffs_Device. At the moment a chunk is a page.
-
int WriteChunkToNAND(struct yaffs_DeviceStruct *dev,int chunkInNAND, const __u8 *data, yaffs_Spare *spare)
-
int ReadChunkFromNAND(struct yaffs_DeviceStruct *dev,int chunkInNAND, __u8 *data, yaffs_Spare *spare);
-
int EraseBlockInNAND(struct yaffs_DeviceStruct *dev,int blockInNAND);
-
int InitialiseNAND(struct yaffs_DeviceStruct *dev);
In the Readxxx and Writexxx functions, the data and/or spare pointers may be NULL in which case these data transfers are ignored.
A quick note about NAND:
-
NAND is not random access, but page oriented. Thus, we do all reads & writes in pages.
-
Each NAND page holds 512 bytes of data and 16 "spare" bytes. Yaffs structures the spare area with tags used to identify what is stored in the data area. There are 32 such pages to a block.
-
NAND writes will only change 1 bits to 0. eg. if a byte holds 10110011 and you write 11011010 to it you will get the logical and of the two values: 10010010. The only way to get 1s again is to erase the entire block.
-
You may only write to a page a few times before erasing the entire block. Yaffs lives within these limitations. Each page only gets written to twice (once when written and once when discarded).
-
ECC is normally used with NAND to correct for single bit errors. YAFFS applies the ECC itself, so the MTD should not do this.
-
The current mtd interfaces are not particularly well suited to YAFFS and we will address the issue with the mtd group. (The mtd interface does not support page-oriented read/write which YAFFS would prefer).
mkyaffs
mkyaffs is the tool to format a NAND mtd to be used for YAFFS. This is quite simple, just erase all the undamaged blocks. YAFFS treats erased blocks as free (empty) space.
Expected performance
The following numbers should give an indication of the performance we should expect from YAFFS.
As an example, I'll use the following numbers. Since the hardware is capable of 50ns read/write, these numbers allow for some other ovberheads. Clearly though, the performance can be degraded in various ways.
Seek10uS/page
|
Read |
100nS/byte |
|
Write |
100nS/byte |
|
Program |
200uS/page |
|
Erase |
2mS/block |
From this we can derive some higher-level numbers:
OperationTimeCalculation
|
Read spare |
12uS |
seek + 16 * read |
|
Read page |
63 uS |
seek + 528 * read |
|
Write page |
326 uS |
seek + 528 * write + program + read page (for verification) |
|
Discard page |
212 uS |
seek + 16 * write + program |
|
Overwrite page |
538 uS |
write page + discard page |
|
Erase overhead per page |
63uS |
erase/32 |
From this we can infer the following flash access times:
OperationTimeCalculation
|
Read 1MB file |
0.13s (about 7.5 MB/s) |
2000 * read page |
|
Write 1MB (clean system) |
0.53s (about 1.8 MB/s) |
2000 * write page |
|
Overwrite 1MB file (no gc) |
1.08s (about 0.9MB/s) |
2000 * overwrite page |
|
Overwrite 1MB with 50% gc |
2.4s (about 0.4 MB/s) |
2000 * overwrite page + 2000 * page copy (== overwrite page) + 4000 * erase overhead |
|
Delete 1MB file |
0.43s (about 2.2 MB/s) |
2000 * discard page |
|
Delete 1MB file with 50% gc |
0.49s (about 2.0MB/s) |
2000 * discard page + 1000 * erase overhead |